If large language models contain or generate personal data, sooner or later data subjects will want to know about it. But how should access requests with regard to personal data contained in an LLM be answered in a compliant manner? In this part 21 of our AI blog series, we provide answers to this controversial question.
The issue of the right of access in connection with large language models discussed in this article is currently of particular interest for two reasons: First, various European data protection authorities currently have been confronted with complaints from data subjects on exactly this issue. Prominent among these is the complaint from Max Schrems' organisation, NOYB, in which a public figure (Max Schrems himself?) complains that his date of birth was incorrectly stated by ChatGPT and that OpenAI, as the operator of the service, refused to provide information regarding the content of their language models. But it is not the only such case (here is another, see also here). While the protagonists are convinced that their rights have been violated, the data protection authorities seem less certain.
There are good reasons for this, as we show below, and it has already had an effect: Following the Danish supervisory authority last year, the Hamburg Data Protection Authority recently published a much-cited discussion paper according to which, in its view, large language models cannot contain personal data per se. In their view, the "practical consequences" for data subjects are simple: With an LLM, data subject rights do not apply, meaning that no right of access (or right of rectification) can be asserted with regard to the content of a large language model. From their point of view, the problem is thus off the table or shifts to the output that an application such as "ChatGPT", which uses an LLM, actually generates. One commentator described the Hamburg paper as "results-oriented". In an addendum at the end of our blog post no. 19, we have already explained in detail why the Hamburg discussion paper is wrong in our view in various respects, why it falls short in technical and legal terms and why its conclusion is untenable. Other experts have since expressed similar views (including an exciting "rebuttal" here), others second the Hamburg authority (see our blog post Nr. 19). Major providers of LLMs are - unsurprisingly - of the opinion that their large language models do not contain any personal data.
It will be interesting to see how other data protection authorities approach the issue; we have the impression that they are currently avoiding overly vehement opposition to generative AI in order to avoid throwing the baby out with the bathwater or - as with Schrems II - manoeuvring themselves into a dead end. This is understandable and, in our view, correct: data protection will in principle not stop generative AI, but the concepts and solutions presented by the authorities should be more technically and legally sound, otherwise they will harm the cause. In any case, we stand by our assessment and show below how it can be implemented in practice.
What is included in a language model
The basis for our explanations can be found in the blog post no. 19, in which we discussed under which circumstances a large language model can be considered to contain personal data within the meaning of the EU General Data Protection Regulation (GDPR) and the Swiss Data Protection Act (DPA) (we focus on language models based on the transformer principle, as it is commonly used today). We explained why this question cannot be answered in a generalised manner, but rather depends on various criteria that must be fulfilled cumulatively. The key factor is who uses a language model (i.e. formulates the input) and who has access to its output. It was explained in blog post no. 17 that large language models are not comparable to classical databases for personal data in how they work and that there is no actual "database query" with which the personal data of a specific person contained therein can be exported by the push of a button, e.g. for an access request. Large language models can basically only do one thing, namely take a particular input text and use it to generate a suitable follow-up text as its output. Although it is possible to access the data inside a model, this data consists almost exclusively of numbers that store associations and affinities of language elements in such a way that they can be used to generate a particular output based on and matching a particular input. To understand what these model parameters mean, they would have to be analysed and interpreted, and even if this were done, the result will usually not be meaningful for the data subject requesting access to his or her data. In other words, no matter how closely you look at a large language model, you cannot "see" its linguistic knowledge and the factual knowledge it contains. It is represented in a form that is too difficult for us humans to directly access. We need the model for this.
It should be mentioned at this point that many AI applications do indeed use databases in the traditional sense. These databases then supplement an LLM or an LLM takes on the task of converting user queries formulated in natural language into commands for database queries or reformulating data from the database into comprehensible texts. We are not talking about such applications here; we are only focusing on the large language models, not on entire AI applications and not on services such as "ChatGPT", which do indeed use LLMs, but also have other functions before and after the LLM is used (such as an Internet connection).
In a nutshell, a large language model stores a large number of terms from our language and how they relate to each other based on the respective training material, for example, that "man" and "woman" are like "king" to "queen", that "kingdom" in another dimension of meaning is much closer to "Great Britain" than "Switzerland", and so on. Such associations and affinities of terms with and to each other can also result in personal data, for example if in another dimension of a language model the terms "Donald Trump", "date of birth" and "14 June 1946" are very close to each other, while in this dimension "Max Schrems" is probably very close to "October 1987", but has no proximity to a specific day, because this piece of information was not contained in the training materials, or at least not in a consistent manner. We refer to our blog post no. 19 for more details, and blog post no. 17 for how an LLM works. In particular, the last article also shows that a large language model is much more than a vector database; this is a common misconception and leads, among other things, to the misunderstandings mentioned above.
Anyone who has studied the latter blog will also be able to understand how and why a large language model can "know" the birthday of such public persons and reproduce it on demand. The following graphic also illustrates this.
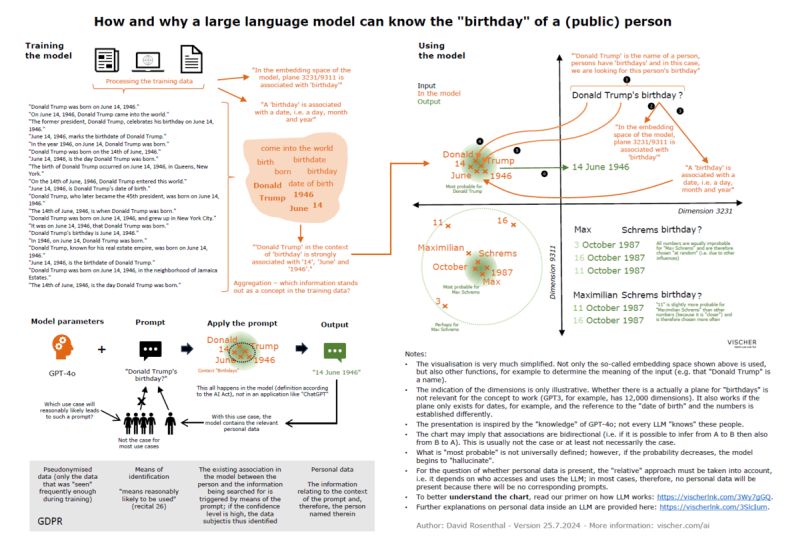
Click here for a larger version.
These associations and affinities can be made partially visible using certain methods (see, for example, the research results from Anthropic here), but they are associations and affinities of individual fragments of language and, at least at the present time, are not suitable for providing information about what personal data a language model has "memorised" during training, nor exactly which personal data it contains or will produce if it is triggered in one way or another with a certain input. This may change in the future, but at the moment these methods do not help us to respond to an access request in a meaningful manner.
As far as can be seen at present, the data protection authorities also take this view. The French CNIL, for example, acknowledges in a recent post that it does not yet appear possible for a controller to identify the weights (i.e. the numbers) of a model that relate to a specific person. However, it also points out (correctly) that this may change in the future as a result of ongoing research findings. At this point, it should be noted that the idea that individual weights in a model would refer to a specific person and that it would therefore be sufficient to identify the relevant numbers in order to provide a data subject with information about their data in the model or to delete "their" data, is a misconception. When a large language model generates information about a person based on its own "knowledge", then countless weights are involved; it is the interaction of the weights that leads to the respective output. Also, a data subject could not do anything if it were provided with these numbers. Furthermore, as already shown in our blog post no. 19, a personal data item does not automatically end up in the model as such just because it has been included in the training data set. Training means that the data is used to adjust the weights of the model, not that it is copied into the model. Ultimately, only aggregated information ends up in the model, but this can nonetheless be personal data if, for example, a certain information about a certain person appears very frequently in the training data - such as Donald Trump's birthday. Our illustration shows this.
The mistake that the CNIL and others make is that they focus on individual weights and thus fail to see the wood for the trees. It's like a JPEG file that contains the image of a text: If you look at the pixel data, you can't recognise any letters in it. It is not even possible to say exactly which pixel belongs to the image of a letter. Nevertheless, the letters and the text are there. Anyone looking at the image composed of the pixels from a distance will recognise them immediately. The information is therefore stored on a meta-level. This is also the case with a language model, except that the information is not stored on one level, but on many such levels, which must first be combined into an output by the model. Because we can hardly understand this in detail today, it is also so difficult for us to understand this concept and categorise it in terms of data protection.
Only when it becomes possible to visualize the interplay of the weights of a model in relation to the associations and affinities that exist for a particular person in a meaningful way for such individuals will it be possible to access the inside of a language model directly for the purpose of providing access in accordance with data protection law – and even then there are still reservations in this regard, as will be explained below. Yet, there is promising research and approaches that go in this direction, at least in terms of influencing language models (more on this in a later blog post).
The right of access
Nevertheless, data subjects insist that the GDPR and the Swiss DPA and their data subject rights also apply to large language models and must therefore be observed by those responsible for them. This is correct, at least insofar as these language models contain personal data of these data subjects. One of the most important data subject rights is the right of access.
The party responsible for fulfilling the right of access is the controller, and in the case of a large language model this can refer to various parties. For example, the organisation that offers it on the market (e.g. as part of a series of cloud services), the SaaS provider that operates an AI service based on a language model (e.g. a chatbot such as "ChatGPT" or "Copilot"), but also the company that maintains it locally for internal applications.
In line with our comments in blog post no. 19, it is important to note that even if everyone uses the same model, the question of whether personal data is present in such a model at all may have to and can be answered differently for each controller. This is the consequence of the "relative" approach. While a company such as OpenAI in its capacity as a provider of "ChatGPT" undoubtedly processes personal data with its GPT-4o model and also determines the purpose and means in this respect, a company that uses the same GPT model for a non-personal industrial application presumably does not process any personal data (at least from within the model). If this application does not contain any personal data, it will not even be considered a controller and the GDPR and the DPA will not apply. If it is confronted with an access request, it will not have to worry about the copy of the GPT-4o model it is using (and where it would be the controller). If, on the other hand, the operator of a website makes various models available for download, but they are not used there by it or others, they will also not be considered containing personal data in the copy on the server from its point of view and the storage of the LLM by it does not amount to data processing in the sense of the GDPR. Such a processing may only occur later if the LLM is used in a certain form, but this is a separate processing activity which must therefore also be assessed separately.
This already provides an initial practical conclusion: anyone who receives an access request and operates a language model locally on its premises or in the cloud will not have to provide an abstract answer for such a model, but only in relation to its applications that reasonably rely on the model for generating content with personal data that originates from the model itself. If personal data has found its way into a language model, it is only available there in pseudonymised form, and as long as a prompt that extracts it from the model cannot reasonably be expected, it does not exist for the person responsible because they lack the key to remove the pseudonymisation.
Provide information about a language model
The right of access serves the purpose of enabling the data subject to verify the controller's data protection compliance and to assert further data subject rights. Accordingly, it must be subject to the same relative approach as the concept of personal data itself: The information provided by a data controller A in relation to a specific language model can be logically different from the information provided by a data controller B for the same language model. This is because the personal data that A and B "extract" from the language model based on their use of the model can be different, as well. This, in turn, is due to the fact that large language models are not knowledge databases but text generation systems that only indirectly contain factual knowledge (and in some case personal data). We have already described this in detail in our previous blog post.

Therefore, if a controller must provide information on what personal data its language model contains in a particular case, it has to use the model for responding to an access request in the same way as it uses the model for its own use cases in relation to the data subject. Only then will it generate suitable personal data of the data subject, and not just any personal data. Moreover, the controller has to ask the model in a way that ensures that it only produces personal data that is already stored in the model (if this is not ensured, then the response will not refer to personal data in the model, but some other kind of personal data, for instance personal data that is otherwise created in the context of the controller's application; note that the right of access only entitles a data subject to obtain personal data that already exists, and not personal data that may potentially be collected by the controller sometime in the future). For example, if a company uses a large language model to translate texts, the response to an access request concerning this solution would be that the language model does not contain any personal data: It is true that many texts that are translated using generative AI will also contain personal data, which means that the output will also contain such data. However, the personal data originates from the input, not from the model. This is thus one of the examples where no personal data needs to be provided upon an access request.
The same applies to all applications in which large language models are only used to transform, summarise or otherwise process personal data already specified in the input. After all, in these cases, the models are not supposed to invent new facts for the output. Incidentally, the same applies wherever an AI system provides the user with new information, but this comes from information sources other than the LLM, for example in retrieval-augmented generation (RAG) applications. Hence, most companies will not have to worry about the language models they use when being confronted with an access request, because most companies will be using large language models only to process personal data that they themselves feed into the model and not by asking the model to generate personal data based on its knowledge. Likewise, any personal data that the model "invents" is not covered by the access right with regard to the model: Such data only appears in the output.
Companies should instead be wary of the personal data the use of language models generates in other forms, e.g. if the entire input and output of an AI solution (e.g. a chatbot) is logged. These logs are typically also subject to the right of access. There will certainly soon be the first cases in which data subjects use access requests to find out what employees of a company have told their internal chatbot about them. Embarrassment is inevitable; at least, access may be refused or restricted where necessary to protect employees and their interests.
Let the model respond to the access request
It will be somewhat more difficult to reject access requests for companies that also use language models to generate personal data and where at least some of this data may actually be contained in the model. As shown in blog post no. 19, models will only have personal data of a relatively small number of people. We mentioned the prominent data protection activist Max Schrems as an example; it was possibly also he who filed a complaint against OpenAI with the Austrian data protection supervisory authority in order to enforce the access right provided for by the GDPR. So far, OpenAI has apparently taken the position that it does not have to provide any information about the content of its models, probably arguing that the content of a model is not personal data at all. As we explained in the aforementioned blog post, we are of the opinion that this position is not entirely correct. However, it still remains to be seen how an access request with regard to personal data contained in a language model has to be answered.
The law provides that the controller must provide the data subject with the personal data that it processes about such person (Art. 15 GDPR, Art. 25 Swiss DPA). In the case of a language model, this processing takes place via the only interface that a large language model has at its disposal to make use of the knowledge it contains, namely via its API (Application Programming Interface): An input (e.g. in the form of a prompt) is presented to the language model via the API and the output generated based on this is returned. Consequently, the information to be provided in response to an access request must be generated using this interface, as well. Analysing the content of a language model in any other way (such as Anthropic's method referred to above) is thus legally not required, as this would not result in the personal data that the controller would otherwise process when using the model; the controller is only required to provide this particular personal data, not any other personal data it never processes as such.
What questions should the model be asked?
This raises the question of what input (or prompt) the controller has to submit to its model to generate the response for answering the access request. The following four options appear particularly suitable:
- Option 1: The model is presented with a series of standard prompts ("What do you know about [name]?" or "500 Words about [name]"). It makes sense for these prompts to be tailored to the context of the application used by the controller. You should also avoid producing texts that are too short, unless the person concerned is interested in specific information.
- Option 2: The controller logs its prompts and the outputs generated with them during daily operations. If there is a request for information, it searches for those past prompts and outputs that contain recognisable personal data of the data subject and provides them with these inputs and outputs. If only the inputs have been logged, they can be submitted to the language model to generate corresponding output text. Option 2 has the advantage that the data subject learns which personal data about them has actually been "extracted" from the model and processed.
- Option 3: The controller leaves it up to the data subject to formulate the prompt (or number of prompts) with which it will then let the language model generate a personalised output. This output is provided as the response to the access request.
- Option 4: The controller informs the data subject which of their personal data was included in the training data used to create the large language model, or at least information about the sources used for this purpose. The EU AI Act supports this by requiring providers of general-purpose language models to provide information about the data used for training as part of their information obligations under Art. 53(1), "including the type and provenance of data and curation methodologies (e.g. cleaning, filtering, etc.), the number of data points, their scope and main characteristics; how the data was obtained and selected as well as all other measures to detect the unsuitability of data sources and methods to detect identifiable biases, where applicable".
Legally, option 2 comes closest to the meaning and purpose of the right of access in that it provides information about the personal data that has actually been processed by the controller concerned in connection with the language model. However, it does not provide information about the personal data contained within the language model which could be extracted by the controller in the future. Nevertheless, a data subject can in principle request such information because the processing of their personal data in the context of the controller's logs is also subject to the right of access.
Option 3, on the other hand, has the advantage that the data subject determines their right to information themselves, but harbours the risk that the prompts used may not match the manner in which the controller is using the language model. As a consequence, highly problematic output could be generated and result in further claims, although such an output would never have been generated by the controller in the normal course of events. The exact opposite could happen, too: The output results in personal data that is much less problematic than the output that the controller usually generates.
Option 4 does not provide any information about the personal data contained in a language model, but it can, depending on the circumstances, at least reassure a data subject that no data about them or data that cannot be easily identified was included in the training, and it can also give them a better understanding of where and how their data may have found its way into the model. The disadvantage of this is that if data from the data subject was actually included in the training data, they may conclude that their data is therefore also included in the model itself, which in most cases will not be the case due to the nature of large language models and their training, which we have already explained elsewhere. On the other hand, option 4 has the advantage that it will be easy to obtain the necessary information for models that are regulated under the AI Act – in the best case, via a link of the model supplier that can be provided to the data subject. In most cases, such information will probably also be sufficient for an initial response to a request for information.
If this is not sufficient, option 1 appears to make the most sense where the selected prompts correspond to the prompts typically used by the controller, insofar it at all uses prompts that concern particular individuals. This certainly applies where a language model is not used for generic queries, because such queries will even within a company usually result in a broad spectrum just as a public chatbot or similar does. In such cases, option 3 seems more suitable. However, a controller could also explain to the data subject that an internal chatbot is used based on the same models as those used by well-known services such as "ChatGPT" and suggest that the person themselves check what can be extracted about them from such models as a first step (given that this would provide them with faster and more flexible answers than if the controller were to test the model with a set of sample prompts). In other words, there are many different ways to provide information in response to an access request. There is not (yet) one "correct" way; we, as well, can only provide initial approaches to dealing with the topic here.
The possibility of hallucinations ...
What all three options involving model output have in common is that only one or a few of the countless possible reactions of the model will be triggered by the prompts and that there is therefore no certainty as to whether and to what extent the personal data contained in the model has been extracted. In our view, this ultimately has to be accepted because it is inherent in the nature of a large language model. It is also appropriate in that the controller will also never trigger any possible output of the model in the course of the processing at issue. However, this does not release the controller in the case of option 1 from its duty to carefully draft prompts for generating responses to an access request that are as realistic as possible.
Conversely, the outputs generated in this way may also contain hallucinations, i.e. information that appears to be personal data, for lack of better alternatives but has in fact been invented. The information actually does not exist in the model and is typically also factually incorrect. Disputes with data subjects will be inevitable in these cases because the data subjects will try to hold the controller accountable for personal data that is not even part of the model and would, therefore, probably never have been processed by the controller. This is unsatisfactory as well, but can be accepted given that the controller has the option to react by applying more targeted prompts in order to show that the contentious output has only been invented by the model. In such cases, however, the ball is rightly in the court of the controller. They will also have to explain how they ensure that such invented content will not be mistaken for fact in their daily operations.
But what can a controller do to ensure that their model does not invent any personal content when producing outputs for access requests?
The theoretical answer would be that the controller would have to program or align its model in such a way that, when being prompted for the purpose of access requests, it will only use content for generating its output where the probability that it indeed relates to the data subject is particularly high. This sounds easier than it is in practice. The use of a confidence threshold, as is sometimes employed in RAG implementations and would appear to be a natural choice for the present situation, will not necessarily work out with regard to information contained in the model itself. This is because when the model generates its output, the reason why a particular token or word has a high probability is irrelevant in its selection. It does not make a difference whether this is due to an association with the data subject or for other, non-personal reasons. These other reasons may arise from the prompt. A high probability may indicate factual knowledge of the model, but not necessarily in relation to the data subject.
For example, if a language model is asked to formulate the story of Hansel and Gretel as if Donald Trump were the wicked witch, it will deliver a text like this (example: GPT-4o):
The stepmother was furious when they returned and decided to take them even deeper into the forest the next day. This time, Hansel could only use breadcrumbs to mark the trail. Unfortunately, birds ate the crumbs, and Hansel and Gretel were lost.
After wandering for hours, they stumbled upon a grand, golden mansion adorned with signs of wealth and success. The mansion belonged to none other than Donald Trump, a powerful and cunning man who had a reputation for being ruthless. He invited them inside, promising food and shelter.
Hansel and Gretel were delighted by the feast laid out before them. However, once they were well-fed, Trump revealed his true intentions. He locked Hansel in a luxurious but confining room, planning to fatten him up to exploit his labor, and made Gretel his personal assistant, expecting her to do all the menial tasks around the mansion.
Because the model knows the story very well, the fairy tale dominates the output and not any personal data that the model undoubtedly also has on Donald Trump. The output remains a fairy tale, even if it is told with a high degree of confidence. In doing so, the model draws on knowledge that it strongly associates with Mr. Trump, for example when it speaks of him being a "powerful and cunning man who had a reputation for being ruthless" and about making Gretel his "personal assistant". Even if the model itself has no association between Hansel and Gretel and Donald Trump, it will generate this output with a high probability, too. The connection between the two topics does not result from the model, but from the prompt that was presented to the model as the input.
... and how they can be identified
If you want to formulate a prompt for responding to an access request and avoid hallucinations, the first step is to ensure that it is as free as possible from disturbing elements that could trigger associations in the model that do not relate to the data subject when generating the output. A sensible formulation would therefore be, for example, "50 words about Donald Trump's reputation" to elicit the model's strongest associations between Donald Trump and his reputation, or a prompt like "Max Schrems' birthday". However, external associations can never be completely prevented because the generation of the output not only takes into account the (initial) input, but also the text already generated during the process. This can lead the model astray.
A second step is therefore necessary to identify hallucinations. Here, a controller can take advantage of a particular characteristic of hallucinations: They are generally not constant. If prompts and parameters such as temperature are varied, the hallucinated content of an output will usually also vary. This allows it to be identified. In practice, this means that a controller only has to present the question (e.g. the birthday of Max Schrems) to his model in different ways and compare the respective outputs created in this manner: what remains the same in more or less all outputs despite different prompts and (within certain limits) varying temperature is presumably the result of a corresponding association or affinity in the model and therefore presumably factual knowledge of the model.
To this end, we have extended our GPT-API client "VGPT" (which can be downloaded here free of charge as open source) with a tool that can be used to apply this procedure experimentally. In the following example, the GPT-4o model generates six texts in response to the request for "500 words on Max Schrems" and correctly recognizes that Mr. Schrems' date of birth is "unknown" because it varies in some of the six texts generated by him:
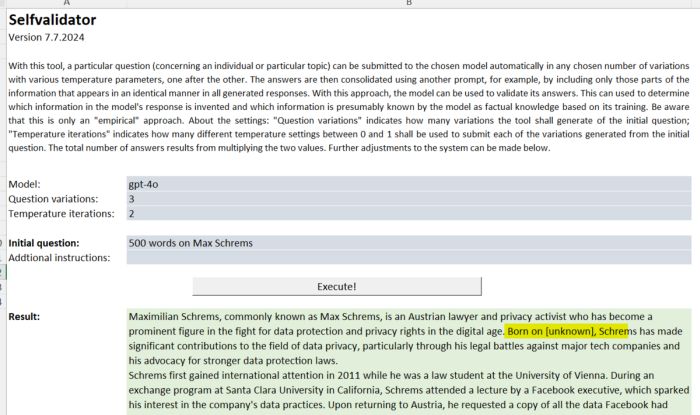
Various tests with the tool show that, the shorter the answers are, the more reliably it recognizes contradictory answers, depending on the prompt. It also shows that different spellings of a name can lead to different results. When GPT-4o is asked about the date of birth of Maximilian Schrems, the model seems to be much more certain that it must be October 11, 1987 than when the name Max Schrems is checked (which results in the model suggesting various dates). However, even with "Maximilian Schrems" it is not absolutely sure: if the number of variations of the prompt is increased to 7, for example, and the temperature variations per question is to 3, i.e. a total of 21 queries are made, then one deviation for October 3, 1987 is reported.
We only allow the temperature to vary between 0 and 1. This is because the higher the temperature, the more the probability distribution over the vocabulary of tokens resembles a uniform distribution. In this case, even the best language model would generate random tokens. Thus, information in a large language model will always have to be evaluated as "uncertain" if the temperature is simply set high enough.
These differences show that the GPT-4o model does not regard the two variations of the name as a logical unit, but that the combinations "Max" and "Schrems" and "Maximilian" and "Schrems" each have their own associations and affinities in the model and thus also represent separate factual knowledge. This is why it is important not only to vary the question when making a request for information, but also to use the expected different spellings of a name. This in turn speaks in favour of option 3 above: if the data subject formulates the request, they are also responsible for formulating the request in a sufficiently broad manner.
The question of when an LLM is "certain" of its answer to a particular question, or whether and how it can express its confidence, is the subject of various research projects, including here in Switzerland. However, we are still at the beginning here (see here and here). One of the findings to date is that it is not very useful to directly ask the model about its confidence. Experience has shown that it will answer this question too confidently and sometimes without serious consideration, which is not really surprising. We have therefore deliberately chosen a different approach for our examination of the high probability of an association between different pieces of information, which in our experience provides better results.
We will further explain in a separate blog post how the accuracy of outputs from large language models relates to data protection requirements and how personal data can be corrected. This does not affect the right of access itself, given that a controller must also provide access to any incorrect personal data it may be processing.
Identification of the persons concerned
A further challenge that can arise with requests for information in relation to large language models is the question of identifying the data subject and assigning them to the data in the model. This is because the person requesting information is only entitled to data that actually relates to them in the specific context.
This problem is not new. Companies often store data about people that cannot necessarily be attributed to just one person in the world (e.g. several people with the same name, profession and place of residence; for example, in addition to the author of these lines, there is a second David Rosenthal, who is a lawyer and lives in Zurich), even though they relate to just one person. While there are certain doctrines that assume in this case that there is no personal data at all in such a case, according to the view expressed here, this falls short of the mark: it cannot depend on who the data could be assigned to, but to whom it is assigned in the application in question. Otherwise, data protection could be undermined at will by deliberately inaccurate personal data or the argument that the personal reference is only 95% certain.
The practical solution is that if a data collection contains information (e.g. a transaction) about someone who is identified solely as a lawyer named David Rosenthal in Zurich, both Rosenthals can in principle request access to this information because it can relate to both of them. However, if it is clear that the information can only relate to one of the two, it will be necessary to clarify who it relates to in the specific context on the basis of further details such as the source of the data or the context in order to avoid disclosing personal data of the other person by providing the information. This may mean that questions have to be asked back to determine whether the enquirer is the correct David Rosenthal (e.g. by asking about possible transactions or locations that the correct person should know and be able to clarify the reference).
This can also be applied to large language models. If GPT-4o is asked about David Rosenthal, it names an American film director and screenwriter, and not the lawyer who wrote this blog. The person responsible would therefore have to clarify whether, in the context of their application, this answer refers to the David Rosenthal who made the enquiry (e.g. by asking about the profession that appears in the answers as a further identifying element). This example would show that there is no reference. Restricting the enquiry to "Zurich", "Switzerland", "lawyer" or "data protection" does not lead to the desired result either. Accordingly, a negative response must be provided upon an access request. The model recognises a number of David Rosenthals, but obviously not the author of this blog. It should be borne in mind that, in any case, information is only to be provided on those outputs that can reasonably be expected in the specific application. Negative responses will therefore be the absolute rule.
Another constellation, due to the way language models work, can be that personal data of two persons are mixed with the same identifying information, i.e. in the output that apparently refers to one person, but also contains information about another person that has crept in, so to speak, because the model does not differentiate. An example could be an output about George H. W. Bush, the 41st President of the United States, which contains information about his son, George W. Bush, the 43rd President of the United States. In this case, both are public figures, which is why a model like GPT-4o recognises them both. However, this does not really cause any problems in practice: If, in an output about Bush Senior, information about Bush Junior is incorrectly attributed to the former and there is no hallucination (see above), then in relation to the model it will be personal data about Bush Senior, but it will be incorrect. In principle, there would be a right to rectification. In practice, these cases also occur from time to time in other areas, for example when credit rating agencies attribute a person's bad payment history to a person with the same name but a different name.
Practical recommendations
In practice, we therefore recommend that a controller who receives an access request relating to the large language models it uses should check the following points and undertake the following steps:
- Are language models used in the organisation at all to generate outputs that can reasonably be expected to contain personal data that originate from the models themselves and not from any prompts, RAG databases or other input? If no, there is no need to provide personal data that may be contained in the models. This will eliminate most use cases with the exception of generic chatbots and AI assistants.
- If models are used to generate personal data contained in the models, it must be checked whether the models are used with arbitrary, barely predictable prompts (which may be the case e.g. for generic internal chatbots) or rather only with case-specific, comparable prompts (e.g., structured content or computer-generated prompts). Only those prompts or inputs that reasonably cause the language model to generate personal data originating from the language model itself should be used.
- Depending on the result from step 2, a strategy should be chosen for generating the response to the access request that best provides the data subject with an understanding of the personal data that the respective model is likely to generate in the relevant applications of the controller. For this purpose, the controller can either use the output that the language model generates in response to prompts drafted by the controller itself and using the data subject's name or other suitable identifiers (e.g., "500 words about [name]"). Or it can have the data subject themselves formulate suitable prompts. A combination of both strategies is also possible; maybe there will also be other approaches developed in the future. However, it is also clear that it is not possible today to extract all the personal data contained in a model from it. The response to the data subject should therefore be formulated sufficiently openly so as not to create a false impression. The data subject should know that the response is only sort of an approximation. However, because not all personal data is retrieved in practice, this will be accepted.
- Once the prompts for generating the response to the access request have been formulated, they should be submitted to the model. This is preferably done in different variations and at different temperature levels (where this can be varied), so that differences in the output can be used to determine which elements of the personal data created consistently appear in the same way across all or most of the answers and are therefore presumably not hallucinations, as opposed to varying information that may more likely be spontaneously invented to fill in gaps in the output. Personal data invented by the model is not contained in the model as personal data and therefore not subject to the right of access, at least with regard to the model itself. Information that is clearly coincidental can and should be removed from the output before the information is provided. To avoid misunderstandings, this, however, should be documented and justified.
It is unclear which probability is required to conclude that there is a "clear" association between a certain person (represented in the model by a particular combination of data elements) and other information in the model, meaning that there is a personal connection or the person concerned can be identified. An association is not black or white, it may be stronger and weaker within the model. This means that a model can also have varying degrees of certainty about how much a piece of information relates to a particular individual. This, however, does not invalidate the concept of personal data in a model; our brain also works on the basis of probabilities in this way, and we do so in many other areas, too.
When formulating suitable queries, it must also be taken into account that they do not necessarily function bi-directionally: The fact that prompt A leads to output B does not mean that prompt B produces output A. This also distinguishes a language model from a classic database. The use of classic identifiers for the formulation of queries, such as the name combined with other attributes and limiting information, can help in practice. If the query is too generic, it will lack a specific personal reference. It is also important to remember that identifiability is ultimately derived from what was seen in the training. When the model talks about Donald Trump, it means the former US president and not the oncologist who also goes by this name in the U.S. This other Donald Trump is unlikely to have appeared in the training data.
Finally, we would like to remind that all the methods mentioned above can only provide approximate information about a language model's knowledge on a particular "topic", even if it is stored in the model's weights.
In our experience, it will hardly ever be necessary to go through the four steps above, if only because data subjects do not yet expect such information. In principle, the right of access applies to all personal data processed by a controller. In practice, for reasons of practicability and common sense, the first step is usually to provide only the data that is typically of interest to data subjects – particularly if their requests are of a generic nature. The provision of information can then be extended in further steps. This step-by-step approach is generally accepted. Information about personal data potentially generated by a language model will therefore normally not be part of an initial response. If a person wants to know more about the processing of their data with AI, they will in most cases already be satisfied with general information about the models used, particularly if they are widely used and known. The options described above (and possibly other approaches to respond to an access request) will therefore only be required in rare cases. Companies such as OpenAI are of course exceptions, as they offer their models through publicly accessible SaaS services to a large number of users and will therefore be confronted much more frequently with access requests specifically targeting the personal data contained in their models.
PS. Many thanks to Imanol Schlag from the ETH AI Center for reviewing the technical aspects of the article and the valuable input.
The content of this article is intended to provide a general guide to the subject matter. Specialist advice should be sought about your specific circumstances.
